When coding, do you find AI assistants either too slow to keep your flow or not smart enough to produce quality code? Cursor’s newly released Composer model breaks this dilemma by leveraging reinforcement learning (RL) technology to achieve a peak in both intelligence and speed—boasting a programming efficiency four times that of models with equivalent intelligence, while precisely adapting to real codebase standards.

Have you ever wondered why AI programming assistants often feel “almost there”? They are either smart but frustratingly slow, or quick but produce code that just doesn’t feel right. This contradiction troubled me until I saw Cursor’s AI researcher Sasha Rush share insights at Ray Summit 2025. They introduced a new model called Cursor Composer, which solves this problem with a completely different approach: training an AI agent that is both smart and fast through reinforcement learning (RL).
After listening to the entire presentation, my biggest takeaway was that this is not just a technical advancement but a shift in mindset. The Cursor team is not chasing generic benchmark scores but focusing on solving real-world programming issues. They use reinforcement learning to train the model in real codebase environments, allowing it to understand coding standards, learn to use various tools, and know when to execute tasks in parallel. More importantly, they integrated the entire product infrastructure into the training process, allowing the AI to behave like a real user using Cursor during training. This “training as product” philosophy made me rethink how AI tools should be built.
Why We Need a Fast and Smart Programming AI
Sasha Rush opened the presentation by noting that Cursor Composer performs almost on par with the best Frontier models in their internal benchmarks, outperforming all models released last summer. Its performance is significantly better than the best open-source models and those marketed as “fast.” What’s truly impressive is that this model’s token generation efficiency is four times that of models with equivalent intelligence. This means it is not only smart but incredibly fast, even outpacing products specifically designed for rapid coding.
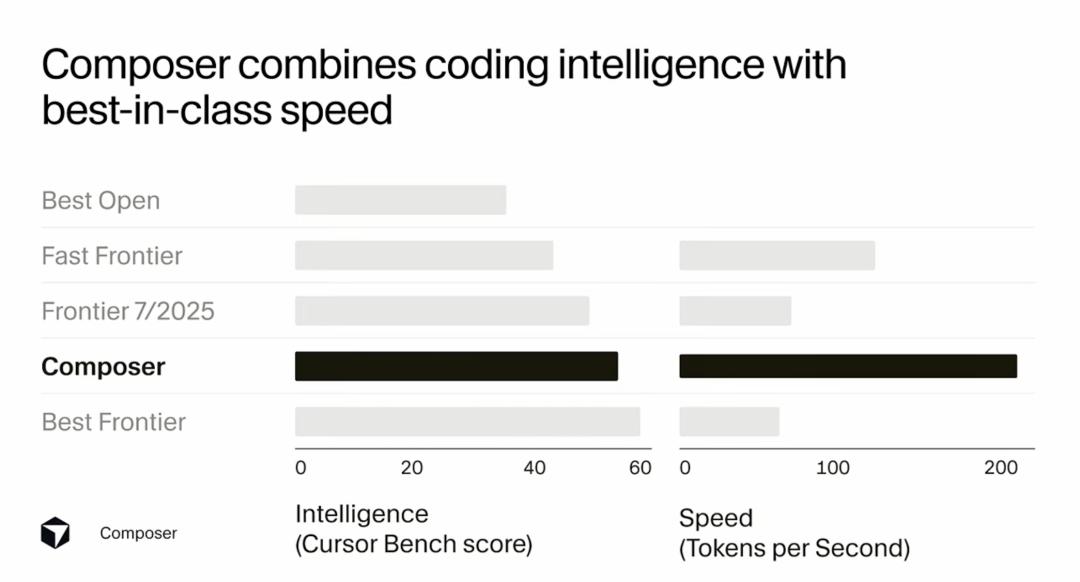
I have always believed that the “speed” of AI tools is not just a technical metric but a core aspect of user experience. Imagine you’re coding and suddenly need to refactor a complex function. If the AI assistant takes 30 seconds to provide suggestions, that’s enough time to break your concentration. However, if the AI can respond in 2 seconds, you can maintain your flow and stay immersed in coding. This “speed that doesn’t interrupt your thought process” is the real value.
The Cursor team understands this deeply. Their inspiration came from one of the most popular features in the Cursor application: Cursor Tab. It’s a fast, intelligent model that feels very smooth and enjoyable for users. Sasha Rush mentioned that making the model fast enough to support interactive use helps developers maintain their thought chain and stay in a workflow state. They aimed to build an agent model that offers a similar experience. They created a prototype model, codenamed Cheetah, specifically designed to provide a fast experience for agentic coding. After releasing this prototype, user feedback was overwhelmingly positive, with many saying it felt “completely different,” even like “alien technology.” This convinced them that building a smarter model while maintaining the same efficiency would lead to a revolutionary experience.

I particularly resonate with Sasha Rush’s point: they are not pursuing arbitrary benchmark scores but are focused on creating a model that feels good to use in real programming work. They built an internal benchmark from their own codebase to measure the model’s ability to work within large codebases and whether it adheres to the codebase’s standards. These intelligent factors are what truly matter in everyday software engineering. Many times, AI models score high in standard tests but perform mediocrely in real work scenarios because they are not optimized for actual workflows.

The Cursor team’s goals are dual: to be both intelligent and fast. “Fast” means not only efficiently generating tokens but also running very quickly in the editor. This requires the model to produce edits rapidly and utilize techniques like parallel tool calling to generate results quickly. When you combine these two objectives, you get a model that feels entirely different in practice. In demonstration videos, users submit a query and immediately see the model calling multiple tools, executing terminal commands, searching in the codebase, making edits, and writing to-do items, all culminating in a complete edit and summary of code changes in just one or two seconds. This experience is completely different from typical editor agents used daily.
Agent RL: Making AI Work Like Real Developers
Sasha Rush spent considerable time explaining how they use agent RL (agent reinforcement learning) to train Composer. I found this part particularly enlightening as it reveals the mindset required to build genuinely useful AI tools.
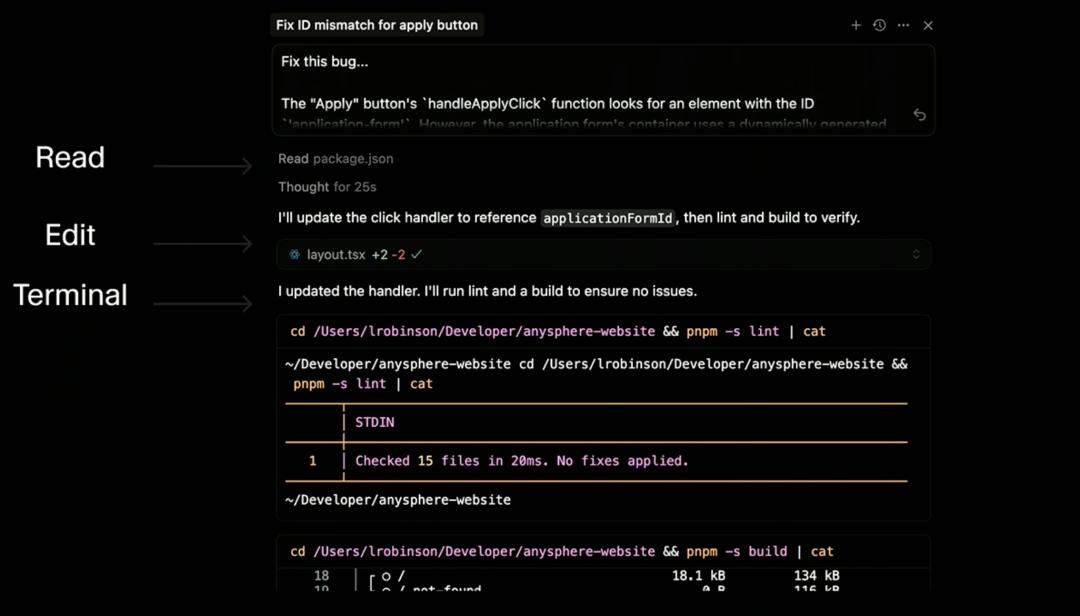
From the user perspective, the workflow with Cursor is straightforward: users submit a query to the Cursor backend, and the agent reads the query and performs a series of tool calls. Sasha Rush explained that we can primarily understand the agent as interacting within a “tool space.” It can choose from a set of tools that can alter the user’s code. In reality, Cursor uses about 10 tools, but we can simplify this to include reading files, editing files, searching the codebase, collecting lints, and executing terminal commands. The agent can call these tools serially or in parallel if it believes that will yield better results.
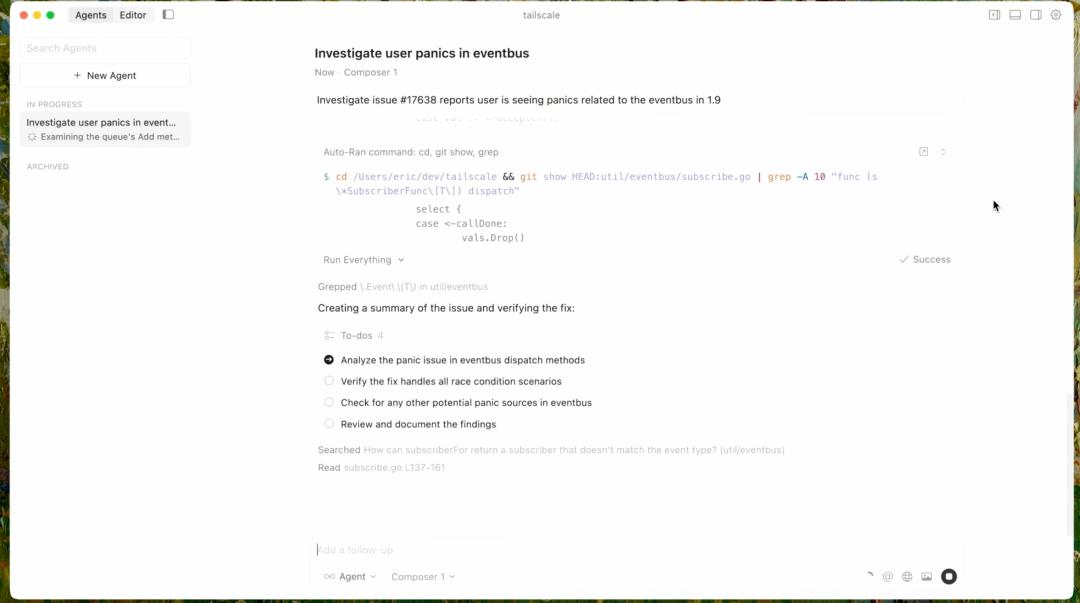
At its core, this agent is still just a large language model generating tokens. Some of these tokens can be understood as forming XML patterns that enable it to call tools and their parameters. However, from a reinforcement learning perspective, we can primarily understand it as taking actions in the combination space of tool calls. When you look at Cursor’s frontend, what you see in these rollouts is the process of combining all different tool calls to make changes. For reading operations, the frontend simply summarizes them; for editing, you see the entire change in real-time; and for terminal calls, you see both the tool calls and the terminal outputs. This is essentially how the agent acts in your IDE world.

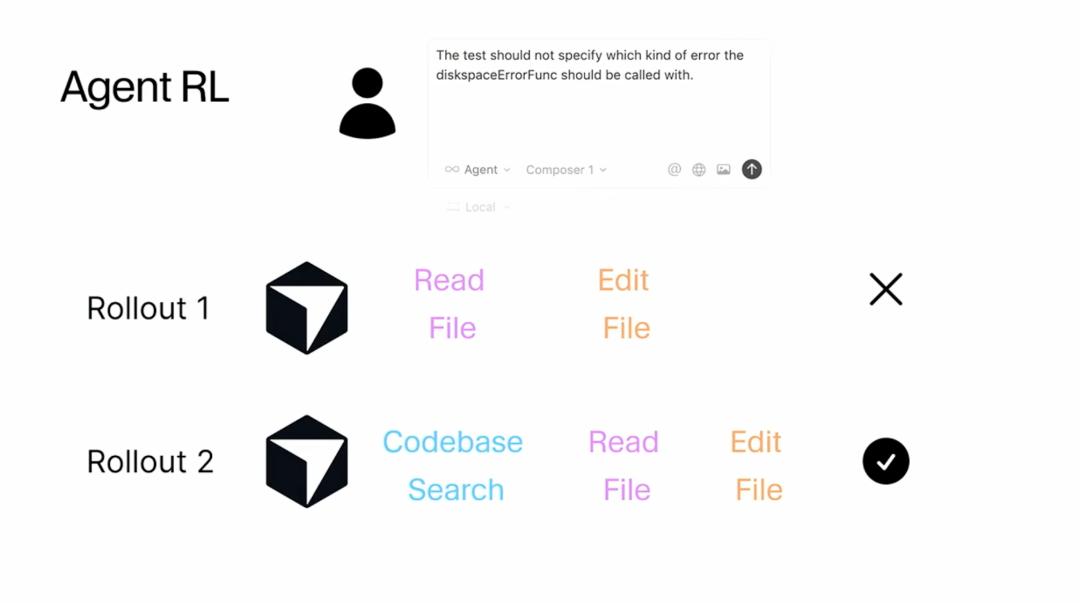
What I find most interesting is how they conduct reinforcement learning training. Sasha Rush emphasized that they strive to simulate the way Cursor operates in production as closely as possible. This means they treat training data as user queries sent to the model, and the agent calls a series of tools to attempt to achieve the goal. However, the difference with reinforcement learning is that they perform many different rollouts from the same starting point. You can think of this as running many instances of Cursor in parallel. In rollout 1, the model might read a file and then edit it. But in rollout 2, due to the probabilistic nature of LLMs, it might follow a different sequence of tools and paths. They then score the outputs of these two choices to determine that rollout 2 is better than rollout 1, and update the model parameters based on this change.
It sounds simple, right? But Sasha Rush noted that all the interesting challenges arise from how to scale this basic process to the extreme, and each step of the scaling process presents its own challenges. This reminds me that often the core ideas of technology may be simple, but the real difficulty lies in how to execute them to the fullest and make them practically applicable.
Three Major Challenges: Matching Training and Inference, Long Rollouts, and Consistency
Sasha Rush elaborated on three core challenges encountered in this agent-style reinforcement learning. I find these challenges highly representative; they apply not only to programming AI but also to nearly all scenarios that require training AI agents in real environments.
The first challenge is matching training and inference. They need to train a mixture of experts language model for optimal parallel performance, which requires distributed training across thousands of GPUs. If you’re just doing pre-training or supervised fine-tuning, that’s already challenging enough, but it’s doubly difficult when doing reinforcement learning because you must have both a training version and a sampling version that must work in sync. I believe this challenge reveals a deeper issue: the model used in real products and the model used in training must maintain a high degree of consistency in architecture, behavior, and performance; otherwise, what is trained may not work at all in production.

The second challenge is long rollouts. When they train with real coding changes, rollouts are much more complicated than those demonstrated. In modern models, rollouts use 100,000 to 1,000,000 tokens and involve hundreds of different tool calls throughout the process. Complicating matters further, different rollouts may involve varying numbers of tool calls, potentially requiring very different amounts of time. This reminds me that real-world tasks are often much more complex than we imagine. A seemingly simple request like “refactor this function” may require the AI to read a dozen related files, search for usage examples in the codebase, run tests, check lints, and only then make the correct modifications. If training only uses simple toy examples, the model will never learn to handle such complexity.

The third challenge is consistency. What they are doing is essentially “training through product production.” They have a Cursor agent and want to simulate it as closely as possible in reinforcement learning. This means they want to use the exact same tool formats and responses as in the production product but on a larger scale. This challenge is particularly interesting because it breaks the boundaries of traditional machine learning. Typically, we separate training environments from production environments, but the Cursor team chose to keep them as consistent as possible. The benefit of this approach is that every technique and tool usage learned during training can directly transfer to the real product.

Sasha Rush emphasized that all three of these issues reflect challenges in scaling machine learning systems, but the actual solutions to these challenges are infrastructure choices. I completely agree with this viewpoint. Often, we view machine learning as purely algorithmic and mathematical problems, but in reality, whether an idea can be turned into a genuinely useful product often depends on how robust and flexible your infrastructure is.
Infrastructure: The Key to Making the Impossible Possible
Sasha Rush spent a lot of time discussing their infrastructure architecture, which I find very worthwhile to understand in depth, as it demonstrates what is needed to build genuinely scalable AI systems.

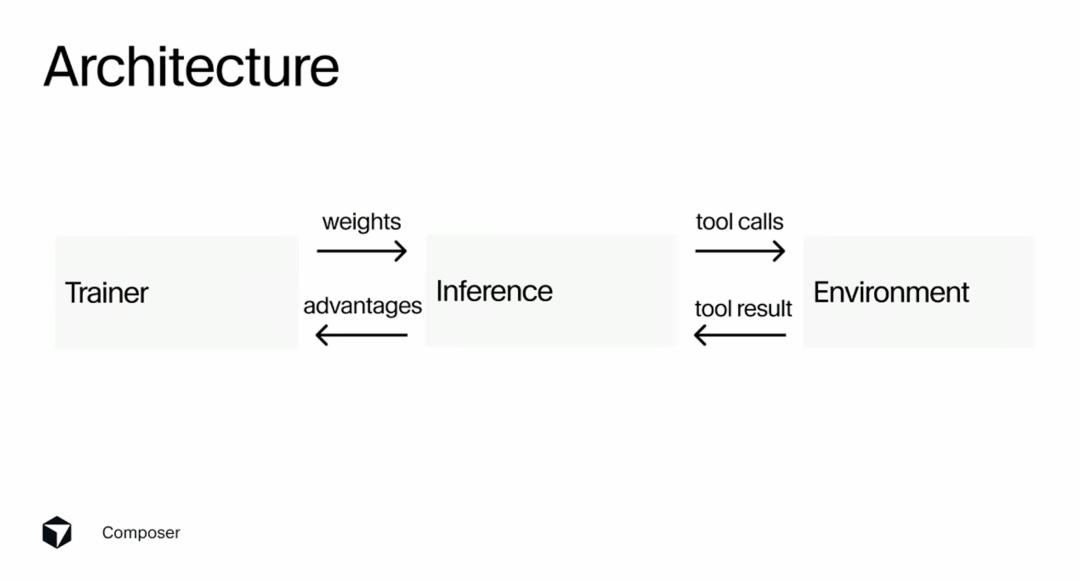
At a high level, they have three different servers: the trainer, inference server, and environment server. The trainer primarily uses PyTorch and resembles a standard machine learning stack scaled to a very large size. The inference server mainly uses Ray to orchestrate rollouts. The environment server uses microVMs to launch stateful versions of these environments, allowing them to make file changes, run terminal commands, and execute linters. You can think of this as running a mini version of Cursor. These three parts need to interact with each other to form a complete training loop.

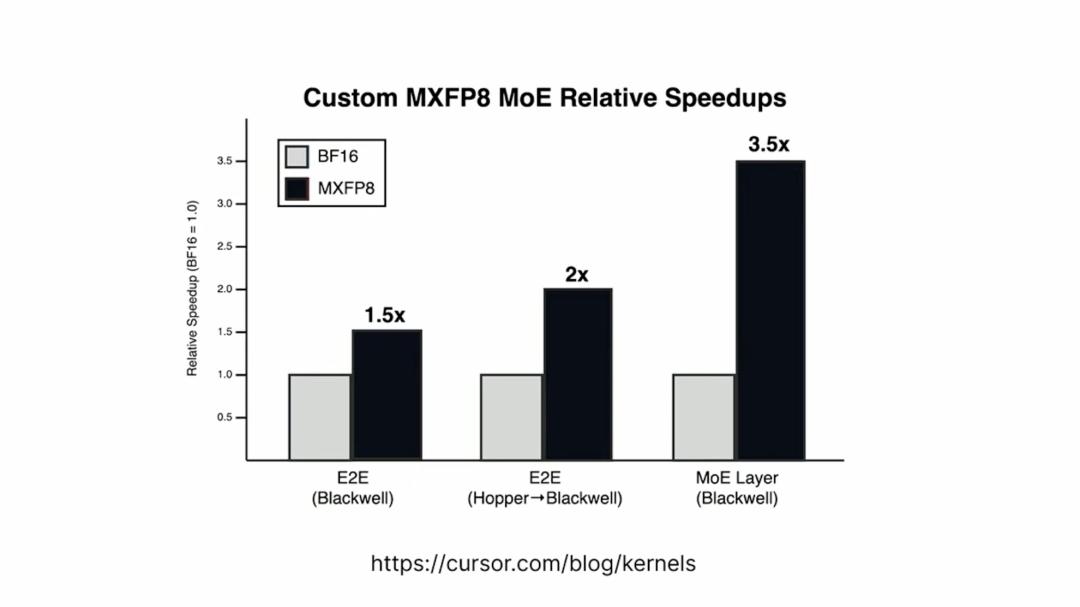
Regarding the trainer, they made a very interesting optimization: they developed a custom kernel library that supports low-precision training. Low-precision training speeds up the training process and allows them to run sampling efficiently without requiring any post-training quantization. They use a microscaling format called MXFP8. The idea is that they can work with FP8 precision but utilize an additional scaling factor to achieve better precision and higher quality training. Sasha Rush mentioned that they developed a custom kernel using this microscaling format for the latest NVIDIA architectures, providing a 3.5x speedup on Blackwell chips for the mixture of experts layer.
I believe this focus on low-level optimization is crucial. Many AI teams might be satisfied with using off-the-shelf training frameworks and standard precision, but the Cursor team chose to dive deep into kernel-level optimizations. This investment not only brought significant speed improvements but also enabled them to train larger, more complex models while maintaining efficiency in both training and inference. This “refusal to settle” attitude is, in my opinion, a common trait of top teams.
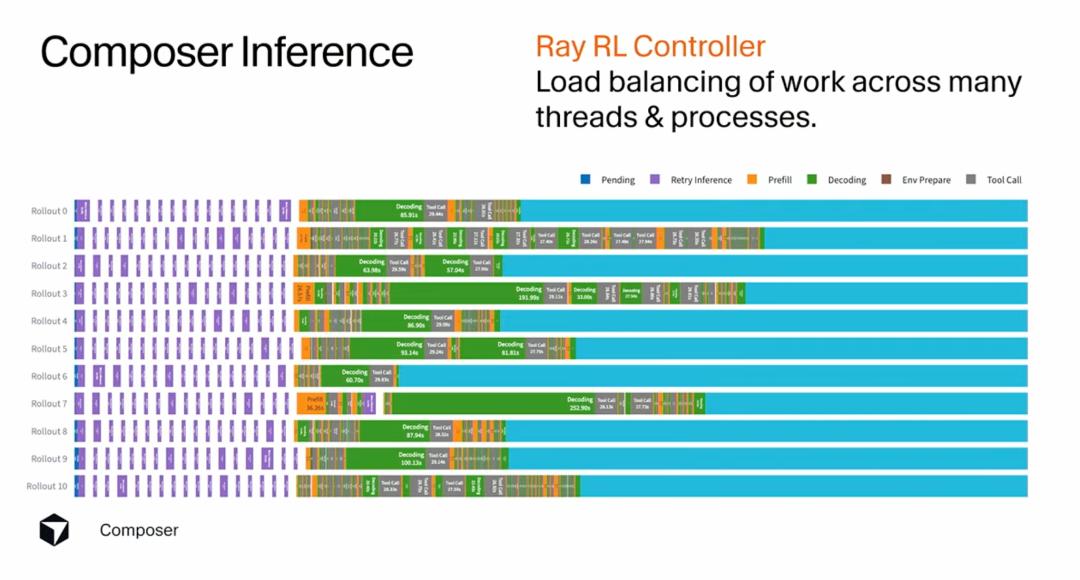
The inference server faces the primary challenge of stragglers (processes that lag behind). If you don’t think through this process and just let the agent do its thing, you will encounter issues. This is because rollouts may call terminal commands and install entire libraries; they can do whatever they want. So if you run 10 rollouts, they may return at different times. They addressed this issue by using Ray and a single controller interface, allowing them to balance the load across many different threads and processes, making this part of the process efficient.
I find this issue particularly illustrative of the complexities of real-world AI systems. Ideally, all rollouts should take about the same amount of time, but in reality, they can vary widely. Some may complete by reading just a few files, while others may require running complex build processes. If you cannot effectively manage this heterogeneity, the entire training process will be dragged down by the slowest rollout, leading to wasted resources and inefficiencies.
Perfect Integration with Production Environment: The Philosophy of Training as Product
One point that Sasha Rush emphasized left a strong impression on me: their goal is to train through the production of the Cursor product. One interesting aspect of Cursor is that they can simultaneously design the product itself and the machine learning training. Fortunately, during the process of building the reinforcement learning stack, Cursor released a product called cloud agents. This allows offline use of the agent, and Sasha Rush mentioned he often uses it to check model performance while commuting on the subway. As part of this product, they launch virtual machines of user environments, allowing the agent to change code and execute terminal commands. They can use the same infrastructure for reinforcement learning training.
This means they have a production agent server that is identical when running the cloud agent and during reinforcement learning training. I think this is a very clever design decision. Many companies completely separate training environments from production environments, leading to models trained that do not perform as expected in real products. But Cursor chose to keep them entirely consistent, so the model learns how to perform better in real products during training.
Of course, this also brings challenges. The workload during peak reinforcement learning training can be much more bursty than running a standard product. So they must handle this burstiness when launching many environments for training, ensuring the product runs smoothly. Sasha Rush showcased a dashboard they built with Composer that displays backend utilization. I find this detail interesting as it shows they have begun using the tools they built to improve their workflows.
You might wonder why it’s worth spending so much time actually using the real production environment. They could simulate all these different structures or attempt to mimic how it works. But Sasha Rush provided a compelling reason: they can introduce specific tools they believe are very valuable for the agent. One of these is that they trained their own embedding model for powerful semantic search. When you use Cursor, it indexes all your files, allowing the agent to query in natural language to find files it might want to edit.
They found that this semantic search capability is beneficial for all the different agents used in Cursor but particularly advantageous for Composer. This is because they can train the model as an advanced user of this tool using exactly the same model and structure as in production. This realization made me understand that AI tools not only need to be smart but also need to know how to effectively use the tools available to them. Just as a great developer not only understands programming languages but also knows how to use IDEs, debuggers, version control systems, etc., a great AI agent also needs to learn how to fully utilize its toolbox.
Performance of Composer One Week After Release: RL Really Works
Sasha Rush shared some observations from the first week after Composer’s release, which deepened my understanding of the potential of reinforcement learning.
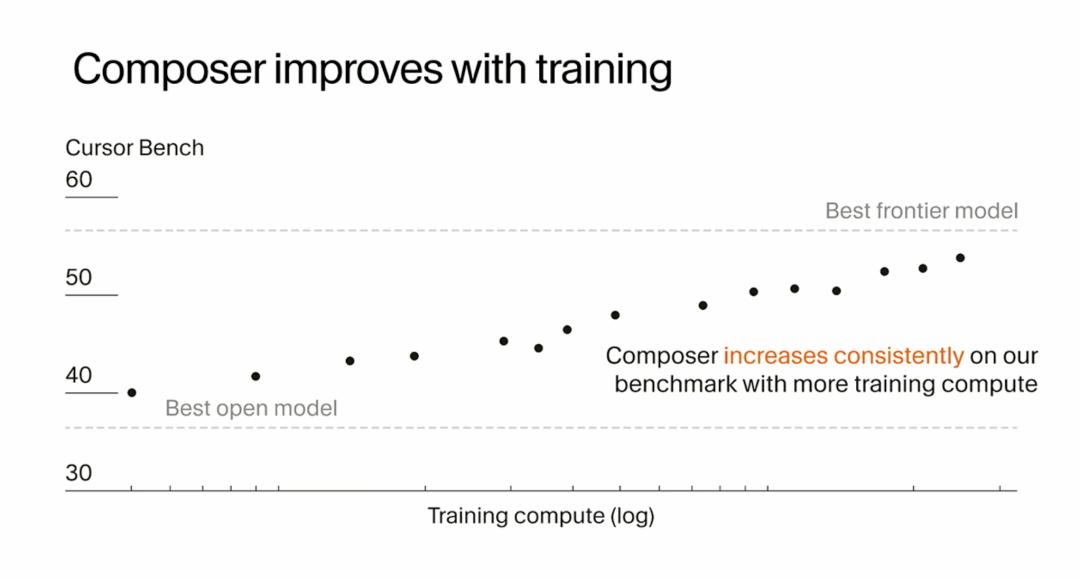
The primary evidence that convinced them of the effectiveness of reinforcement learning is the improvement in model performance as they ran increasingly longer rollout-check-update cycles. The model’s initial performance was roughly on par with the best open-source models in the field, but as training progressed, its performance on benchmarks steadily improved. The x-axis of this graph is a logarithmic scale of computational volume, so they invested significant computation in the reinforcement learning process. But they saw returns associated with this computation, with model performance rising to the level of their released version.

I believe this is a very good signal of the scalability of reinforcement learning, particularly its ability to scale to complex specialized tasks. Many people question whether reinforcement learning can work on complex real-world tasks, but Cursor’s experience shows that with sufficient computational resources and the right infrastructure, reinforcement learning can indeed bring models to the forefront in specific domains.
They also found that they could train the model to act in ways they deemed useful from a product perspective. Sasha Rush previously mentioned that they wanted the model to be fast not only in generating tokens but also in the end-to-end user experience. One key component of this is enabling the model to call parallel tools. As training progressed, the model was able to call more parallel tools and respond to user queries faster. They believe they can further advance this in future training.
I find this discovery particularly valuable because it indicates that reinforcement learning can not only enhance the model’s “intelligence” but also shape its behavioral patterns. Through appropriate reward design, you can teach the model to work more efficiently, such as parallelizing tasks and prioritizing critical steps. This behavioral optimization is challenging to achieve with traditional supervised learning.

They also found that the model learned better agent behaviors. Initially, it made too many edits without sufficient evidence. As training progressed, the model began to read more files and conduct more searches to find the correct editing locations and make appropriate changes. This reminds me that good programming is not just about writing code; it’s more about understanding context, finding the right places, and making reasonable decisions. Composer learned these “soft skills” through reinforcement learning.
Perhaps most importantly, users seem to love it. They released Composer a week ago, and the primary feedback is that the combination of speed and intelligence unlocks a different way of programming. People are no longer starting an agent and then scrolling through Twitter while waiting for results; they are quickly getting results and moving on to the next question. As a programmer and developer, this is genuinely exciting. Sasha Rush noted that many internal developers are now using it in their daily work. I believe this is the best validation of a product: when the people building the tools are using it every day.
My Thoughts on Building Specialized AI Models
After listening to Sasha Rush’s presentation, I have several profound insights to share.
First, I believe that reinforcement learning is indeed very suitable for building such specialized models. This is a paradigm shift we have seen in the development of large language models over the past few years. Reinforcement learning facilitates the ability to build highly intelligent target models in specific customized domains. In the past, we always pursued general models that could do everything, but Cursor’s experience suggests that models deeply optimized for specific tasks may outperform general models in those tasks. This makes me think that perhaps in the future, we will see more of these specialized models: ones dedicated to data analysis, front-end development, system architecture, each excelling in its own field.
Another aspect that fascinates me is how AI systems have changed the process of research and development itself. Sasha Rush mentioned that he and many in the team now have their daily work assisted by the same agents they are building. They use these agents to build dashboards, backend systems, and various other components. This allows them to act quickly with a small team. I find this a very interesting bootstrap process: the AI tools you build not only serve users but also serve you, enabling you to improve this tool more rapidly. This positive feedback loop may accelerate the evolution of AI tools.
Finally, while Sasha Rush mentioned that he is not fundamentally an infrastructure expert, seeing how much reinforcement learning is driven by infrastructure development was an eye-opener for him. It is indeed challenging, requiring the integration of product, scale, and machine learning training. It touches on all aspects of modern software systems. I completely agree with this observation. In my view, future AI companies will need not only excellent machine learning researchers but also world-class infrastructure engineers. Companies that can successfully combine both will hold a significant competitive advantage.

From a broader perspective, the story of Cursor Composer made me rethink how AI tools should be built. The traditional approach is to first train a general model and then adapt it to specific tasks through fine-tuning or prompt engineering. However, Cursor took a completely different path: designing the entire system from the ground up for a specific task (programming), including model architecture, training methods, infrastructure, and product integration. This end-to-end thinking is, I believe, the correct way to build genuinely useful AI tools.
I am also contemplating the limitations of this approach. Reinforcement learning requires substantial computational resources, complex infrastructure, and tight integration of product and training. This means not every company can adopt this method. But for those with the resources and determination, this may be the best path to creating industry-leading AI products. Cursor has already proven that this path is viable, and I believe we will see more companies following suit.
Another question worth pondering is what the future of these specialized models will look like. Cursor Composer focuses on programming, but can the same approach be applied to other fields? For instance, models specifically designed for data analysis, content creation, customer support, etc. I believe the answer is yes, but each field will require its own infrastructure, tool ecosystem, and training methods. This is not an easy task, but for those who can achieve it, the rewards will be substantial.

Finally, I want to say that the success of Cursor Composer reaffirms a principle: true innovation often does not come from following current trends but from deeply understanding user needs and relentlessly striving to meet those needs. The Cursor team was not misled by the narrative that “bigger models are better” but focused on solving the real pain points of developers: how to make AI programming assistants both smart and fast. They achieved this goal through reinforcement learning, custom infrastructure, product integration, and various other means, ultimately delivering a product that users genuinely enjoy using. This user-centered, problem-oriented mindset is something all product developers should learn from.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.