The Entrepreneurial Aura
Yang Zhilin is developing a typical entrepreneurial aura. In an industry focused on technology, he discusses reasoning, agents, and the AI-driven research and development of the coming years. Meanwhile, Kimi has rapidly launched a series of new features: KimiCode for writing documents, creating PPTs, handling spreadsheets, and coding; Kimi Claw for automatically scraping web information; Deep Research for in-depth information retrieval; and Agent Swarm for complex tasks involving multiple AIs.
This leads to a smooth conclusion: Kimi is transitioning from a star model company to a next-generation productivity platform. While this assessment is correct, it is not entirely complete. As Kimi aims to evolve from merely answering questions to becoming an execution platform for knowledge work, it enters a battleground not easily won by technological breakthroughs alone. Competing against not just a few major model companies, but a host of giants that control developer access, office entry, and enterprise workflows adds to the challenge.
Kimi’s difficulties lie not only in the strength of its competitors but also in its simultaneous pursuit of two significant objectives: enhancing its foundational capabilities for complex tasks while also vying for the front-end access to knowledge work. Other companies either already possess this access or are climbing from the capabilities level, while Kimi seems to be pushing itself into the front lines before its foundation is fully established. This path demands high capital intensity, and the speed of building a protective moat may not match the pace of cash burn.
Yang Zhilin excels at steering direction, but a company’s success depends not only on direction but also on harmonizing technology, product, growth, and commercialization. The former resembles a genius’s intuition, while the latter belongs to an entrepreneur’s homework. Rather than having provided a complete answer, Yang Zhilin is approaching the most challenging part of this problem.
The Aura
In March 2026, on the main stage of the NVIDIA GTC conference in Las Vegas, Yang Zhilin sat alongside leaders from OpenAI and DeepMind. This was a standard photo for top AI practitioners globally, but Yang’s identity label was slightly different—he was the only representative from an independent large model startup, while the others were heads of projects under tech giants.
When this photo returned to China, Kimi’s valuation had just surpassed $18 billion, quadrupling in three months and setting one of the fastest records for a Chinese company to reach “decacorn” status (companies valued over $10 billion). However, this identity may soon change again: recent reports from Bloomberg indicated that Kimi had engaged in preliminary discussions with China International Capital Corporation and Goldman Sachs regarding a potential IPO in Hong Kong. With the successes of Zhizhu and MiniMax, it is easy for outsiders to project this glow onto Kimi’s IPO journey.
This is almost a natural extension of the entrepreneurial aura surrounding Yang Zhilin. Among China’s generation of AI entrepreneurs, he is one of the few who cannot be discussed solely within a domestic context. Moreover, on critical issues that determine the upper limits of large model companies, Kimi cannot merely be compared locally.
Dai Yusen, managing partner of ZhenFund, one of Kimi’s early investors, has openly recognized Yang Zhilin, stating that he was regarded as the “God among gods” during his time at Tsinghua University. Such sentiments are not entirely superfluous for understanding Yang Zhilin.
Yang Zhilin’s academic background seems almost tailored for the era of large models. In 2015, he graduated from Tsinghua University’s Computer Science Department and entered Carnegie Mellon University’s Language Technologies Institute with the highest grades in his class. Over the next four years, he consistently appeared on the author lists of top AI conferences such as ICML, NeurIPS, and ICLR, entering the core academic evaluation system early.
More importantly, his contributions are not merely about having published a few good papers. He was involved in proposing Transformer-XL and XLNet as the first author or co-first author, both of which remain indispensable names in the development history of pre-trained models. The former advanced the modeling capabilities of long texts, while the latter is a milestone in the pre-trained model field, directly influencing the technical trajectory of subsequent GPT series.

In 2019, he became one of the youngest field chairs in the history of ACL (Association for Computational Linguistics), and before founding Kimi, he worked at Google Brain and FAIR (Meta’s foundational AI research institute), combining the sharpness of a theoretical researcher with the engineering quality honed in top industrial labs—an experience not commonly found domestically.
Consequently, when evaluating Kimi, discussions often revolve not just around capabilities but also around a more challenging-to-quantify temperament. Perhaps the chief scientist of Manus, Ji Yichao, encapsulated this sentiment with his remark: “Kimi is a company with taste.”
Taste has been frequently mentioned in the venture capital circle over the past two years and is often considered the only moat for AI companies. In March 2026, The New Yorker even stated that “taste” had become Silicon Valley’s new buzzword, gaining popularity akin to the “disruption” of the 2010s.
In Ji Yichao’s view, the embodiment of taste is reflected in a company’s evaluation or internal benchmarks, as the internal metrics—whether for model benchmarks or for individuals—ultimately determine the direction the company and its products should take.
A notable characteristic of Yang Zhilin is that he seems unsatisfied with merely achieving high scores on others’ problems; he always wants to confirm whether the problem itself is correctly posed.
Most publicly available industry benchmarks are fundamentally defined by humans, often leading to inadequate or ineffective benchmarks. Yang Zhilin revealed in a podcast that many companies, in their pursuit of high scores, only tailor their models to perform well in specific scenarios to facilitate press releases, which does not accurately reflect the model’s true performance capabilities. In more out-of-distribution (OOD) scenarios, the performance can be significantly lacking.
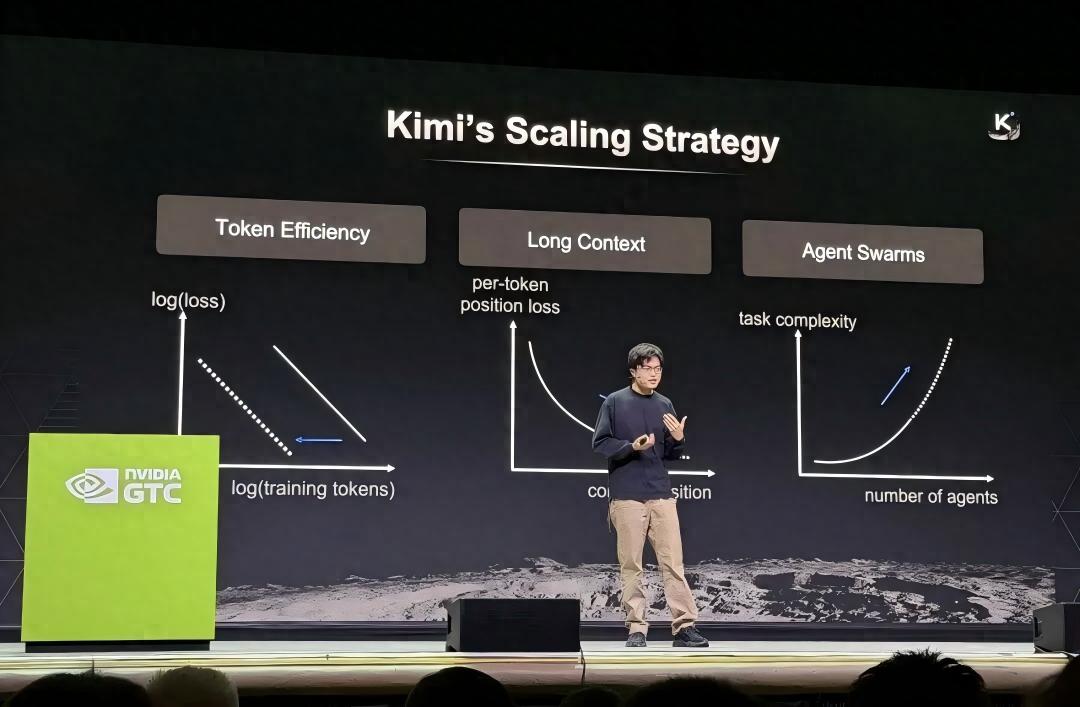
To address this, Kimi has developed a set of benchmarks that more closely align with real work. For instance, in the coding domain, K2.5 does not merely rely on public leaderboards but has designed Kimi Code Bench to measure tasks like building, debugging, refactoring, and testing, which are more aligned with real software engineering tasks. In office scenarios, Kimi has created the AI Office Benchmark and General Agent Benchmark to assess the quality of Office outputs and the completion of multi-step workflows.
Delving deeper, in the training of K2.5’s Agent Swarm, its reward mechanism is not merely about “bringing in more agents” for superficial excitement. It deliberately avoids two situations: many agents appearing to work simultaneously while actually operating serially, or breaking down tasks into ineffective steps just to showcase parallelism, which ultimately slows down overall progress.
This is almost a concrete version of Ji Yichao’s remark: the benchmarks you use will determine the products you train. Kimi does not create a bunch of features first and then find explanations for them; rather, it first decides what capabilities are worth measuring, and only then do products grow along those metrics.
However, this approach also means higher R&D costs, a slower product pace, and a greater demand for continuous realization of foundational model capabilities.
In fact, this is a continuation of Yang Zhilin’s past style. Whether it was Transformer-XL or XLNet, he did not merely push forward along existing paths. The former attempted to resolve why models often struggle to remember or connect when facing longer information; the latter bypassed some inherent flaws in the mainstream pre-training route, rewriting the problem itself.
The commonality of these two works is that they did not settle for making incremental additions within established frameworks but directly challenged the premises accepted by the industry at the time.
This is Yang Zhilin. He never seems satisfied with merely speeding up on an existing track; he always asks, “Are the starting point, rules, and boundaries of this track worth redrawing?”
During his entrepreneurial phase, this habit of “defining the problem before developing technology” became more concrete.
When Kimi entered the public eye in 2023 with its long text capabilities, Yang Zhilin focused not only on being able to handle more content but also on a more fundamental issue: as information increases and tasks lengthen, can the model still maintain coherence and continuity?
Looking back today, Kimi’s homepage showcases not just a chat interface but a whole array of capability modules: Docs, Slides, Sheets, Deep Research, Kimi Code, Kimi Claw, and Agent Swarm. On the surface, it appears that the number of products has increased; however, at a deeper level, they all address the same question: the true value of the model is not in delivering a beautiful answer at a single moment but in whether it can maintain continuity and coherence when tasks become longer and more complex.
A product attempting to achieve this will inevitably evolve beyond the role of a mere “chat assistant”; it will be pushed step by step into heavier roles: the entry point for knowledge work, a scheduling hub, and even an execution platform.
However, as Kimi transitions from “answering questions” to “scheduling knowledge work,” it cannot merely defend one end: it must enhance its models while also competing for access. Without user relationships, it merely becomes a supplier of others’ capabilities; without foundational capabilities, it cannot uphold its promise of “getting things done.” This implies that Kimi has entered a heavier battle from the very beginning—one with higher capital density and longer realization cycles.
When a company fights two wars simultaneously, money becomes not just a financial issue but a strategic one. Kimi is certainly not worried about survival, but how could it not be short on cash?
How Could It Not Be Short on Cash?
On the last day of 2025, Yang Zhilin released an internal letter revealing that the company’s cash holdings exceeded 10 billion yuan. By comparison, looking at the financial data before their IPO: MiniMax had about 2.49 billion yuan in cash and cash equivalents when it went public in Hong Kong; Zhizhu had about 2.55 billion yuan during the same period. If considering a broader scope of available funds, MiniMax had about 7.21 billion yuan, while Zhizhu had about 3.21 billion yuan.
Thus, Yang Zhilin stated, “We are not in a hurry to go public in the short term.” However, three months later, news about Kimi’s IPO spread rapidly, seemingly contradicting Yang’s earlier statement of “not being in a hurry.”
However, when viewed on the same timeline, these two statements may not truly conflict: the former indicates that Kimi does not need to rush to go public for survival or continuity, while the latter corresponds to the fact that during a window of renewed capital interest in AI, the company has no reason to keep a potentially broader financing channel closed.
It is essential to recognize that being able to avoid the anxiety of immediate survival when going public and preparing for the next more expensive war are two different matters.
Moreover, how could Kimi not be short on cash?
The ongoing changes in the industry are: model companies are competing for access, office giants are swallowing models, and collaborative platforms are integrating AI. These three forces seem to have different directions but fundamentally aim for the same thing: the control point of knowledge work—this is the battlefield where Yang Zhilin currently finds himself.
To put it more directly, everyone wants to transition from “helping users do a little work” to “defining how users do work.”
The reason is straightforward: large models are becoming increasingly intelligent, but “intelligence” does not directly create value. What truly determines whether value can be realized is who can first connect this brain to the hands and feet in the real world.
Like a great plan, if it cannot be executed, it is no different from talking on paper.
A fact that every large model company must confront is that the “pure intellectual rent” at the model layer is rapidly being compressed.
Taking Anthropic as an example: when Anthropic released Claude 3.5 Sonnet in June 2024, the API pricing was $3 per million input tokens and $15 per million output tokens; by 2026, with the release of Claude Sonnet 4.6, the official documentation still listed the price as $3/$15, but the context window had expanded to 1 million tokens, clearly emphasizing agents, coding, and computer use.
In other words, while model capabilities have significantly advanced, the price per unit of “intelligence” has not increased; it seems to be locked down by competition.
In China, the situation is even more pronounced. In 2025, the price war among large models has reached a point where prices are nearly at cost: Alibaba Cloud significantly reduced the price of its Tongyi Qianwen visual understanding model by over 80% in February, while Baidu’s Wenxin 4.5 Turbo and X1 Turbo were priced at 0.8 yuan and 1 yuan per million tokens, respectively, in April. Kimi also lowered its open platform prices in the same month, officially stating that the price for Kimi-latest after automatic caching remains only 1 yuan per million tokens.
According to reports, prior to May 2024, the gross profit margin for large model inference computing power in China was still above 60%. However, after major companies began to lower prices in May, this margin has dropped to negative figures.
On the other hand, leading companies’ paths have become increasingly consistent: they are not just selling tokens but transforming models into systems that can genuinely perform tasks.
OpenAI has separately charged for web search, file search, and containers, directly incorporating tool calls, state management, and multi-step execution into product definitions in the Responses API and Agents SDK. Anthropic, similarly, no longer only charges for model calls but also separately prices web search and code execution, redefining Claude Code not merely as code completion but as capable of reading codebases, modifying across files, running tests, and delivering results.
Google is both selling enhanced search and context caching storage separately within the Gemini API while fully integrating Gemini into Gmail, Docs, Sheets, Meet, and NotebookLM, emphasizing service to every employee and every workflow.
Microsoft has made Copilot a work entry point throughout Microsoft 365, covering chat, search, documents, emails, and agent building; Feishu and DingTalk are also embedding AI into high-frequency work processes like meeting minutes, task reminders, and knowledge Q&A.
Even lightweight players like Notion and Cursor have packaged themselves as “AI workspaces,” focusing on agents, enterprise search, automation, and knowledge spaces.
Kimi has also shifted its focus from API usage to measuring “how many tools I used for you, how much environment I occupied, and how long I ran”: Kimi web search charges $0.005 per call, and search result tokens will continue to be billed; Kimi Claw’s one-click cloud deployment requires Allegretto (monthly $31) or higher membership.

The market is responding with real money: in Microsoft’s second-quarter fiscal report for 2026, Microsoft 365 Copilot’s paid seats reached 15 million, translating to approximately $5.4 billion when annualized; Google successfully transformed the Scaling Law into commercial profits, with Gemini Enterprise reportedly selling over 8 million paid seats, covering more than 2,800 large enterprise clients by early 2026.
Of course, Kimi, which aims to evolve into a “knowledge work execution platform,” has also received good news: according to third-party tracking based on Stripe payment data, Kimi’s individual subscription user orders increased by 8,280% month-on-month in January and rose by another 123.8% in February. In just two months, Kimi’s ranking on the global payment leaderboard skyrocketed from outside the top 100 to 9th place.
According to Gartner, by 2035, agentic AI could contribute about 30% of enterprise application software revenue, exceeding $450 billion.
Thus, a clearer landscape is beginning to emerge: the ultimate competitors for large model companies are rapidly converging. OpenAI, Anthropic, Google, Microsoft, and new players like Kimi may appear to occupy different positions, but they are increasingly engaging in the same business—integrating models into real workflows and competing for the entry points, scheduling authority, and pricing rights of knowledge work. Consequently, they are rewriting each other’s boundaries and becoming competitors.
The speed of cash burn in this war correlates with the size of the competitors, and Kimi must confront several trillion-dollar giants simultaneously; each round of ammunition resupply becomes a matter of life and death.
Different Battles
The most challenging aspect is that despite standing on the same battlefield, the wars they are fighting are not the same.
For most companies, this resembles a single-line competition: some are pushing down from existing entry points, such as Google, Microsoft, and Feishu, which already guard established entry points like Docs, Sheets, Word, and Excel; AI is merely an upgrade for them, not a new frontier.
Others, like Zhizhu and MiniMax, have chosen to climb from the capabilities level, gradually exploring the agent and application layers. OpenAI and Anthropic follow a similar path, starting with models before products, and they have already secured the high ground of developers and code assistants, allowing them to expand outward comfortably.
Notion, Cursor, and Perplexity leverage their existing user bases, not necessarily stronger models, but rather the fact that users are already engaged with them in specific work scenarios.
Each of them has its own base and only needs to focus on amplifying its advantages.
However, Kimi does not have this luxury. For Yang Zhilin, it feels like he is simultaneously managing several battles: he has neither an established office entry point nor is he content to be merely a supplier of foundational capabilities. He wants users to directly delegate work to Kimi, meaning he must prove that the model is strong enough while also demonstrating to users why they should change their existing work habits.
The former cost involves training, inference, infrastructure, and engineering; the latter cost involves product refinement, market education, organizational penetration, and corporate trust. This means Kimi must bear the two most expensive fronts simultaneously: one is the hard cost of the model arms race, and the other is the soft cost of user habit migration.
Google and Microsoft invest tens of billions annually in AI, but their Office 365 and Workspace are already profitable businesses, where AI investment is an “upgrade of existing stock” rather than “creating new increments.”
OpenAI, while lacking a host platform, has surpassed 50 million C-end paid users, generating approximately $2 billion monthly, with annual revenue exceeding $25 billion; Anthropic has recently been reported to have quickly raised its annual revenue to $30 billion, forming a self-sustaining flywheel.
Kimi, however, is different. Its valuation skyrocketed from $4.3 billion to $18 billion in just three months, setting a record for the fastest ascent to “decacorn” status in China, but this highlights the extreme desire of capital for its “multi-front combat” capability—
It must support the trillion-parameter model K2.5 and the computational demands of end-to-end reinforcement learning while enduring an average conversion cycle of 18 months for enterprise clients to transition from trial to full reliance; it must maintain a free strategy for C-end users to capture user engagement while also building enterprise-level private deployment and API service systems.
Industry estimates suggest that its single-year computational expenditure in 2024 will exceed 1 billion yuan, and the ongoing engineering of Agent products, continuous iteration of multimodal capabilities, and expansion into overseas markets will further increase this figure.
The critical point is that this war has no endpoint. Every generation of model capability enhancement necessitates a renewed battle for access; every inch of user habit shift requires ongoing product investment to solidify. Rushing to IPO in the short term seems more like an annotation of “always needing more money.”
The Long and Winding Road
If we understand this competition as a positional battle, Kimi resembles a powerful long-range unit: quick to strike, strong in burst, and direct in tactics, but its supply lines, native territory, and margin for error are far more fragile than its competitors.
Kimi’s blood-generating dilemma is hidden within its most glamorous resume. Despite its valuation exceeding $18 billion, its revenue scale is still a fraction of its competitors. In 2025, Kimi’s estimated C-end subscription revenue was around 200 million yuan (data from the media “Light Cone Intelligence”), and even combined with API revenue, it struggled to reach $100 million.
Even with K2.5’s revenue exceeding the entire year of 2025 within just 20 days of its release in 2026, this explosion reflects more the low base prior rather than a stable business model.
A deeper issue lies in the fact that its users come quickly but leave just as fast: in November 2024, its monthly active users were 36 million, but a year later (Q3 2025), they dropped to less than 10 million.
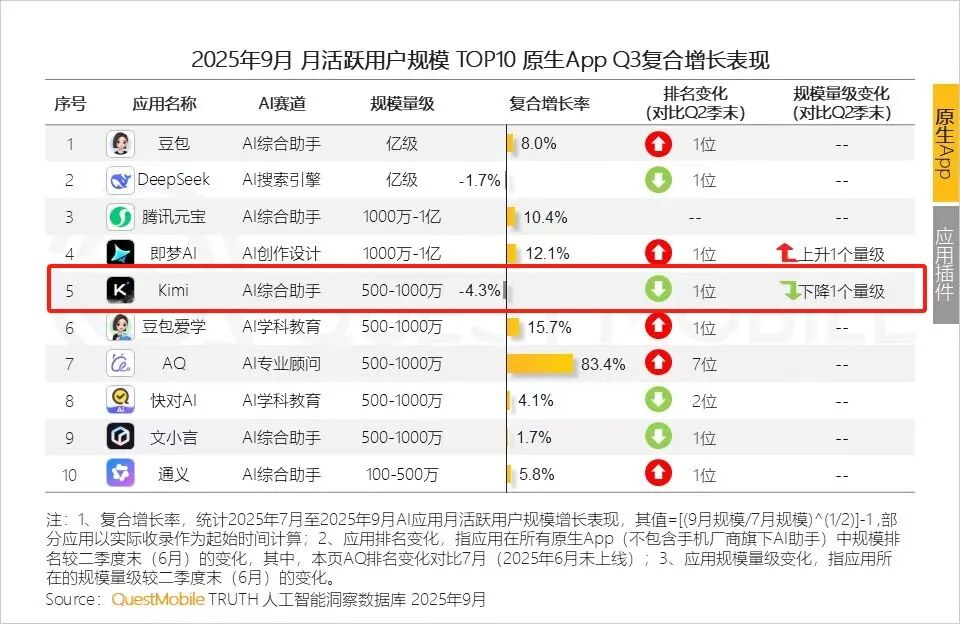
The rollercoaster of data reveals Yang Zhilin’s operational preference: he is more adept at directional judgment and key decision-making rather than gradual rhythm control. In 2024, Kimi was recognized as the industry’s “flow-spending maniac,” with peak monthly expenditures reaching hundreds of millions, with single-month spending in October and November exceeding 200 million.
However, the situation changed in 2025. Giants like ByteDance and Alibaba leveraged their existing traffic entry points and product ecosystems to raise the acquisition costs significantly. For a startup like Kimi, relying solely on spending to acquire users increasingly resembles a bottomless pit.
Simultaneously, DeepSeek rapidly decreased the price of model capabilities with high engineering efficiency. The slight lead Kimi had established through “long text” was quickly diluted.
In this context, Yang Zhilin’s response was not to fine-tune but to hit the brakes: he halted all advertising, paused multiple Android channels and third-party advertising collaborations, and stopped updates on two overseas products. An internal letter explicitly stated, “We do not aim for absolute user numbers.”

The shift from “burning money for growth” to “comprehensive contraction” was abrupt, with almost no transitional phase. This means that the manpower and resources invested earlier did not solidify into sustainable capabilities but were directly wiped out with the strategic shift. On the user side, a vacuum emerged: existing C-end user habits were interrupted, new user education remained incomplete, and brand visibility plummeted.
But the problem does not stop there. More concerning than the growth stall is that Kimi’s revenue structure is not as solid as it appears, especially regarding the overseas business that was highly anticipated.
Kimi’s API revenue quadrupled by the end of 2025, and in early 2026, with the explosive popularity of the open-source agent product OpenClaw, nearly a quarter of token consumption came from that ecosystem, with significant calls also coming from third-party programming tools like Kilo Code.
This means that Kimi’s overseas revenue does not stem from sticky users of its own products but rather from being integrated as foundational capabilities into others’ applications—users do not belong to Kimi, nor does it control the entry points.
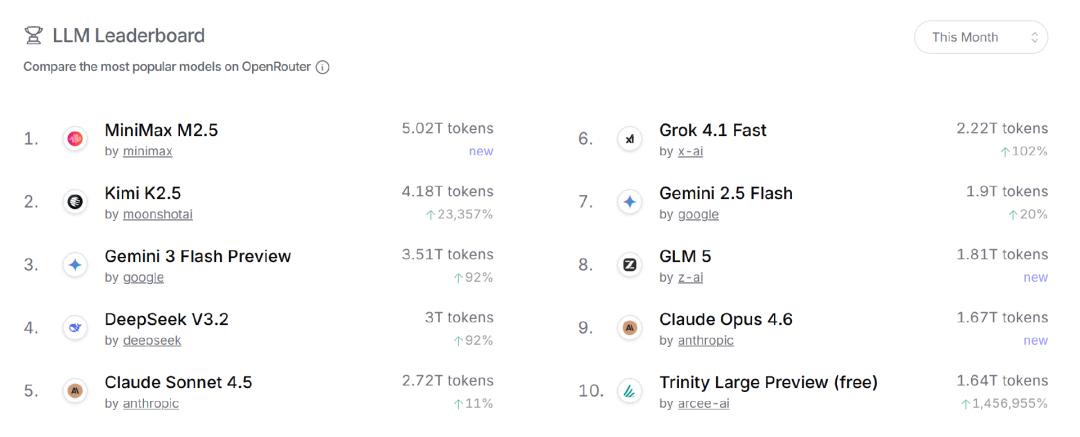
Data from OpenRouter shows that in February of this year, Kimi’s K2.5 model became the second most called in the overseas market.
The biggest issue with this kind of revenue is the limited bargaining space and high substitution risk. If these external products shift to other models, the revenue chain will be severed in an instant.
Meanwhile, its cash burn rate has never slowed down. By the end of 2025, it conducted salary adjustments and stock option incentives for all employees, with plans to double average incentives in 2026; new financing was explicitly earmarked for “expanding GPU capacity and advancing K3 development.” Despite having over 10 billion yuan in cash on the books, it completed two rounds of financing exceeding $1.2 billion within two months.
The ample reserves instead underscore the lack of blood-generating capability; if self-operation were strong, there would be no need to frantically stockpile ammunition.
However, this is the inevitable cost of strategic positioning: lacking existing entry points and failing to establish stable user payment mindsets, while competitors can rely on existing businesses for blood transfusions and lock in users through ecosystems, Kimi can only rely on continuous rounds of financing to fill two bottomless pits.
Dai Yusen once revealed that Yang Zhilin hopes to be recognized as an “entrepreneur” among his labels. However, today, this “genius” is more distinctly characterized by the qualities of an engineer.
In that internal letter at the end of 2025, Yang Zhilin wrote that “surpassing Anthropic to become the world’s leading AGI company” was the most important goal, while emphasizing “not aiming for absolute user numbers but continuously pursuing the upper limits of intelligence,” even clearly mentioning the need for “a bit of obsessive aesthetic persistence.”
Ambition and directional sense remain firm, but in retrospect, the problem lies here: a founder who believes that as long as the model is good enough, other issues will be resolved.
In fact, this mindset not only influences how he views products but also how he organizes the company. When “faster, stronger, and more direct” are prioritized, the organizational structure naturally tilts towards extreme flatness and high-intensity communication.
Reports indicate that Yang Zhilin’s personal motto is “direct communication”; the company has long maintained an extremely flat structure with no middle management, and co-founders directly connect with 40 to 50 colleagues. Such an organization certainly has speed and is well-suited for highly talented, self-driven individuals, but reports also note that as the scale increases, information overload can occur, leaving some employees feeling unmoored due to a lack of clear feedback and certainty.
In other words, he may be more adept at raising standards, compressing links, and approaching the truth but may not be equally skilled at providing a sense of order, security, and sustainable management structure for a larger group.
When a person is prematurely placed in the narrative of “God among gods,” the market tends to overestimate his certainty while underestimating the complexity a company truly faces.
Yang Zhilin believes in a saying: “Problems are inevitable, but problems are soluble.” This quote comes from a book recently favored in Silicon Valley, “The Beginning of Infinity,” written by physicist David Deutsch.
Coincidentally, some critics argue that Deutsch’s book underestimates the friction costs of organization, politics, and human nature in knowledge dissemination—dimensions that technical idealists like Yang Zhilin are prone to overlook.
In response to Zhang Xiaojun’s question about “why AI products have not yet formed a data flywheel,” Yang Zhilin explained: “Because the scaling based on computing power is too powerful… On the other hand, the so-called data flywheel relies heavily on external environmental feedback, which we do not wish to have much noise, but currently, we may not have solved this problem well; large models are still quite sensitive to noise, unlike traditional recommendation systems.”
Simply put, at this stage, the expansion of computing power and the capability improvements brought by reinforcement learning are still very evident; in contrast, enabling models to learn continuously from complex, noisy user feedback has not been genuinely realized.
To some extent, this reliance on “internal certainty” also extends to Yang Zhilin’s way of viewing the external world. He once said he wants to feel what kind of person he is in “his own story.” This statement may not be a form of avoidance but rather his method of handling uncertainty: when the external world continuously raises questions about spending, retention, and commercialization, he prefers to return to those parts he is more familiar with and believes in—technological iteration, capability enhancement, and the ongoing coherence of internal logic.
However, Kimi will eventually step onto a larger stage. The dividends of Scaling Law may not have ended, but whether a company can go far ultimately depends not only on the model itself. Moving forward, real-world feedback, team engagement, and commercial patience will all become equally important variables.
For Yang Zhilin, this may also be another lesson: how to allow parts beyond technology to gradually grow.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.